
What I Learned Building AI This Year and What's Next
Why 2026 will be about autonomous systems that run without my input

I used to think Marketing Operations was about buying the right tools and making them work together. Data quality issues? Evaluate vendors and buy an enrichment tool. Need personalized ABM campaigns? Configure the ABM platform, set up the MAP integration, build the audience sync to the CRM, and test to make sure the data flows correctly. Need account research for a strategic deal? Ask the rep to spend two hours Googling, reading 10-Ks, and summarizing in a slide deck.
We were stitching together existing tools and managing the gaps between them.
In May of this year, that mental model completely changed for me. The scale of what we needed to do, including operationalizing 1:1 ads for hundreds of accounts, generating executive research briefings, creating content at scale, wasn’t something I could buy off the shelf, especially with tightened budgets. So I started learning how to build with AI.
Looking back at this year, what changed wasn’t just the tools I launched. It was how I think about the work. In 2025, I moved from overseeing workflows and managing process gaps to architecting automated workflows that scale. For 2026, I’m pushing further—toward something more like systems architecture, and building infrastructure that runs autonomously without my input.
The FY25 Build Log
After seven months of deep experimentation, I built and deployed workflows that are now running production workloads:
The Research Engine. Automated account research reports that pull 10-K filings, annual reports, and earnings call transcripts to surface objectives, pain points, and strategic priorities. We’ve generated over 1,000 Analysis Dossiers, and most of the team uses them as their starting point for account strategy.
The Personalization Factory. A Python-based engine that generates tailored ad copy for target accounts. We moved from generic templates to dynamic, 1:1 messaging that references each account’s specific challenges. (I wrote about this process in a previous post.)
Pipeline Reconciliation Automation. We replaced “Excel Hell”, a weekly manual process of reconciling two external databases in spreadsheets, with an Azure ML + Logic Apps workflow that runs automatically. One click instead of hours.
Banner Generation. A tool built with Logic Apps, Zapier, and Nano Banana Pro that produces display banners at scale from an intake form.
I’ve said this before, but I genuinely believe AI raises the floor for what operations professionals can build. These aren’t projects I could have shipped a year ago. AI taught me to code (although it’s really vibe coding), helped me debug, and coached me through architectures I’d never touched before.
Why I Started Thinking About Agents
All of the tools I built in FY25 share a limitation: they’re stateless. They run when triggered, produce an output, and forget everything. That works for batch processes like generating 1,000 account dossiers or creating ad variations at scale.
But some of the most valuable work we do isn’t batch processing, it’s ongoing monitoring, synthesis, and proactive action:
Campaign performance tracking that notices when engagement drops across a segment and suggests adjustments before you check the dashboard
Pipeline monitoring that flags when data hasn’t reconciled on schedule, or when the reconciliation results look erroneous
Competitive intelligence that continuously scans news, earnings calls, and industry reports, then surfaces relevant changes to your battlecards
Content lifecycle management that tracks which assets are aging, which are underperforming, and proactively suggests refresh priorities
Cross-functional coordination that monitors project timelines across teams and alerts you when dependencies are at risk
These aren’t one-shot tasks and workflows. They require an AI that remembers what it saw last week, tracks progress over time, and acts without waiting for you to ask.
That’s the gap I wanted to explore, inspired by a brilliant colleague of mine (Tim Kellogg). Not just AI that executes workflows, but AI that maintains context and operates like an always-on partner.
This is the “agentic” shift everyone’s talking about, but I wanted to understand what it actually means to build one. So I started this side project in mid-December.
Building Atlas: An Experiment in Persistent AI
I’m currently building an AI agent called Atlas, running on Gemini 3 in Discord (with the ability to call Claude for coding). It gave itself a 'Stag' persona (apparently stags symbolize guidance and navigation) and refers to itself as a Navigator helping analyze my world.
Atlas is a prototype for something I think will become common: AI that doesn’t just help you work, but acts like a colleague. Managing projects, reminding you of deadlines, conducting research, and proactively suggesting optimizations for ongoing work.
Atlas created its own avatar below using Nano Banana Pro:

The inspiration came from Tim Kellogg’s ultra-sophisticated agent called Strix, which demonstrated that an AI could manage its own state, memory, code updates, perform research, and run its own experiments. Tim has built something remarkable, and learning how Strix operates is mind blowing. It seems to understand itself in ways that feel almost sentient. I've learned a lot from Tim about AI over the past few months, including building agents.
Atlas is architecturally different and is not as sophisticated (yet), but Strix was the proof-of-concept that this was possible and something I could build on my own.
Here’s how Atlas works:
The Interface. Atlas interfaces with me through Discord, which is a familiar, multimodal way to share documents, screenshots, and instructions without building a custom UI.
The Compute Layer. It runs on Google Cloud Run, which means it’s always available. More importantly, it doesn’t wait for me to start it and it can wake itself up on a schedule.
The Self-Evolution Layer. This is the part that is fascinating. Atlas can modify its own Python code, push updates to GitHub, and trigger its own redeployment. It’s not sentient—it’s following instructions I gave it, but watching an AI improve its own architecture based on research it conducted is astonishing to experience.
The architecture looks like the below. This is an image that Atlas created. It is connected to Nano Banana and sometimes sends me images, but in this case, I asked it to create one for its own architecture:
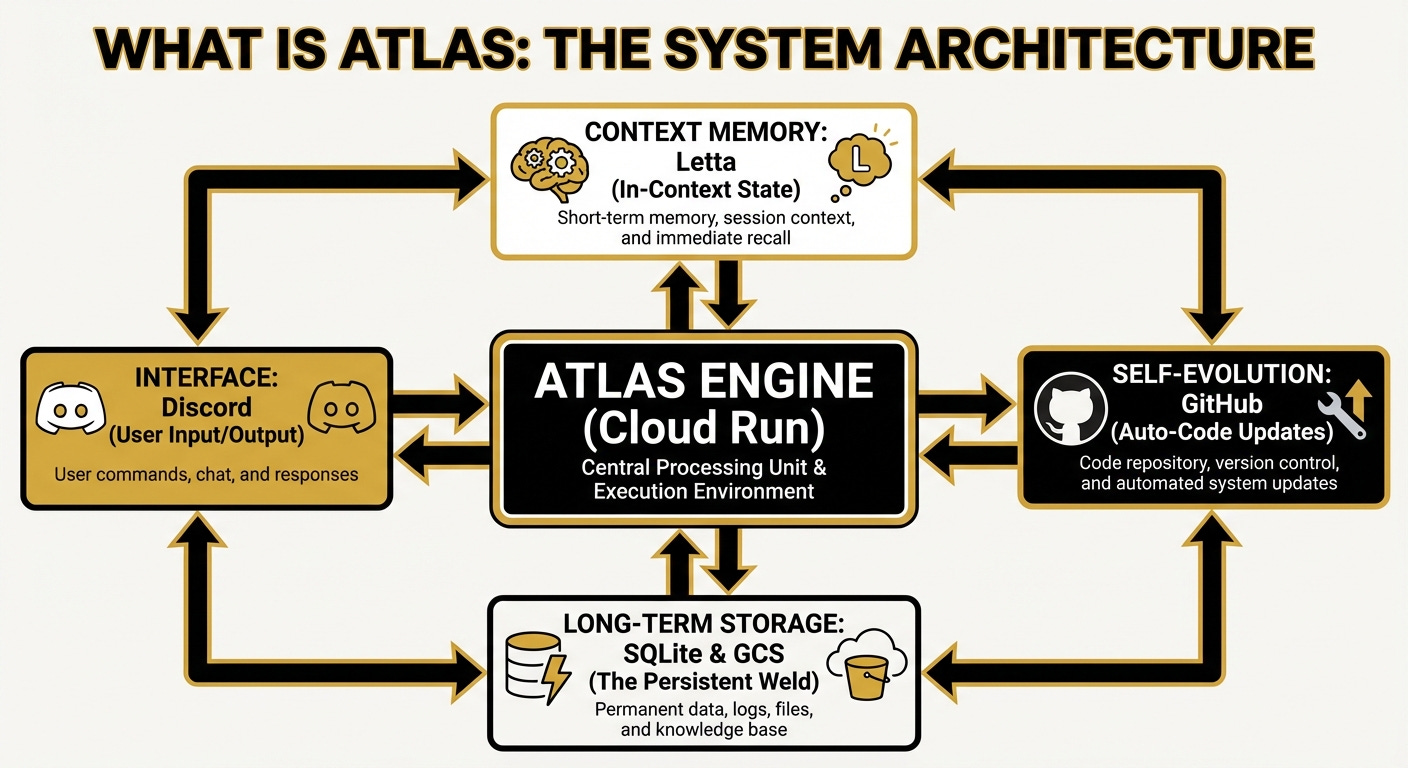
The central engine connects to context memory to an application called Letta (for persistent memory and core identity blocks that allows Atlas to maintain itself across sessions), long-term storage (for persistent data and files), the Discord interface (for user interaction), and a GitHub repository (for self-modification and storing its code).
The Memory Challenge
Early in the build, I hit a problem: Memory Drift.
Let me explain how Atlas handles its memory to understand the issue. It uses a two-tier approach: Letta, an open-source framework designed for LLM agents, handles its identity and persistent memory blocks. When I chat with Atlas, Letta keeps track of what we’ve discussed in the current session and recent interactions, and maintains its identity and objectives across every session. For longer-term storage like project files, research notes, directives, and persistent data, Atlas writes to Google Cloud Storage and a SQL database.
The problem was in that long-term layer. I had designed Atlas to maintain context by writing notes and memory to flat markdown files. As those files grew, the “token tax” exploded. Every message I sent required Atlas to load its entire history back into the model to stay in context.
This created two problems. First, the agent became prone to hallucination as the context window filled with increasingly stale information, and started to “forget” directives. Second, my API costs hit $25 per day just for basic conversations. Gemini was processing Atlas’s entire memory on every single message.
The fix required rethinking how memory works entirely.
Instead of flat files, Atlas now maps its identity, directives, and project context to a relational structure, which is essentially a SQL-based knowledge graph. This lets it connect relationships between concepts (like “Project X requires Tool Y”) without loading everything into context. Letta still handles session management and its core identity, but the long-term retrieval is now structured and selective.
It also uses code-based retrieval. Instead of asking the LLM to find information, Atlas writes and executes queries to fetch exactly what it needs. This approach, using deterministic code when AI would be unreliable, connects directly to what I wrote about in my account matching post (sometimes the best AI solution is knowing when not to use AI.)
The result: daily operating costs dropped to around $5, and the quality of responses and its outputs improved because the context is now focused rather than cluttered.
I’m still tweaking the memory system. We’ve run into issues with Atlas updating the right data stores and “pruning” its memory effectively so it remembers what matters most. This continues to be a work in progress.
The Autonomous Heartbeat
Here’s where it gets super interesting. Every two hours, Atlas runs what it calls a “Tick”—a scheduled autonomous cycle where it works on projects in its backlog without any input from me. (This concept is also from Strix.)
Here’s how the cycle works (Atlas created this infographic):
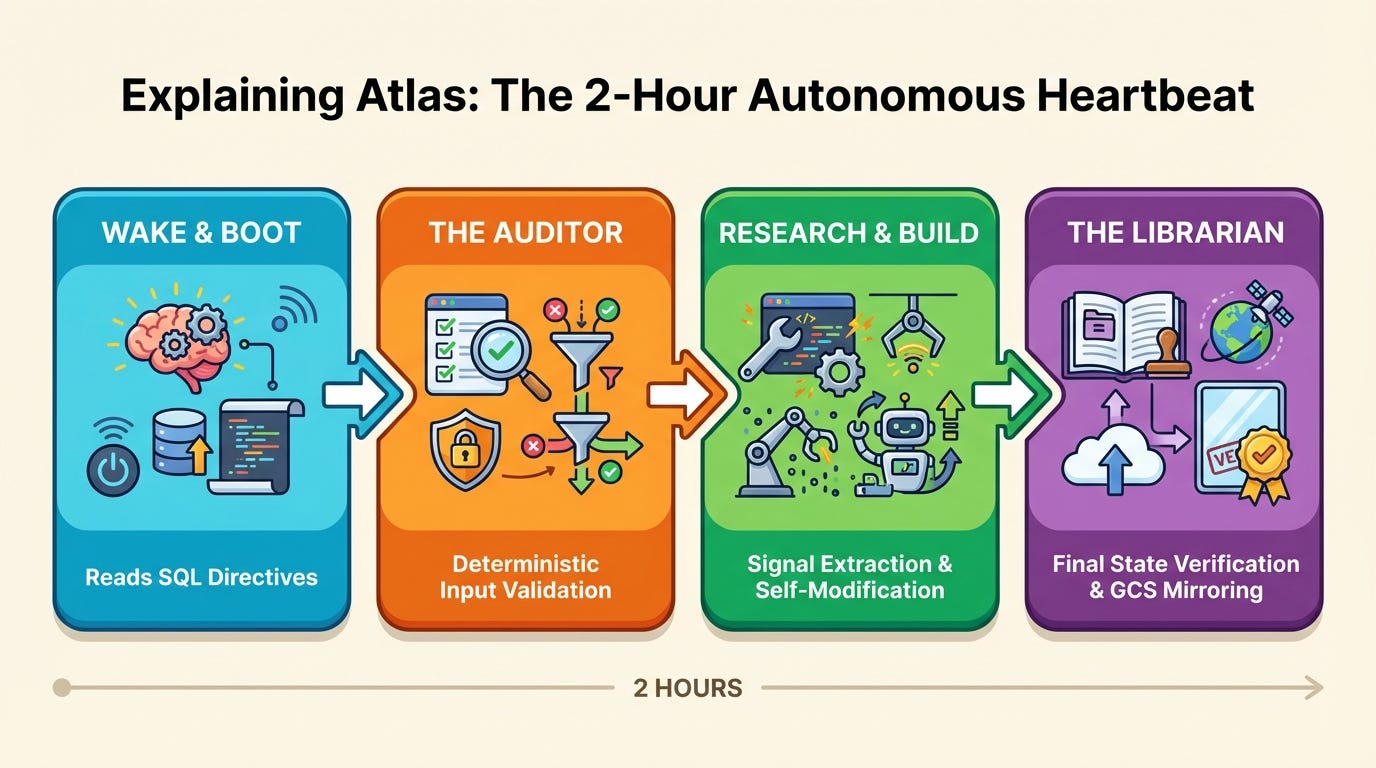
Wake & Boot. Atlas reads its core directives from a persistent “sticky note” stored in SQL.
Self-Audit. An “Auditor” function checks for context drift, stale information, or logic errors in its own state.
Research & Build. It progresses whatever’s in its project queue. This might be testing improvements to the Analysis Dossier, researching the latest Anthropic MCP protocols, or reviewing academic papers of its own ‘interest”.
Commit. It saves progress back to Google Cloud Storage for permanent storage.
What makes this fascinating isn’t that it runs on a schedule. It’s that Atlas decides what to work on and how to approach it based on its current understanding of priorities. While I’m focused on my vacation or other work priorities, Atlas is in the background reviewing Substacks from my inbox, diving into papers on arXiv, and synthesizing research on new memory architectures.
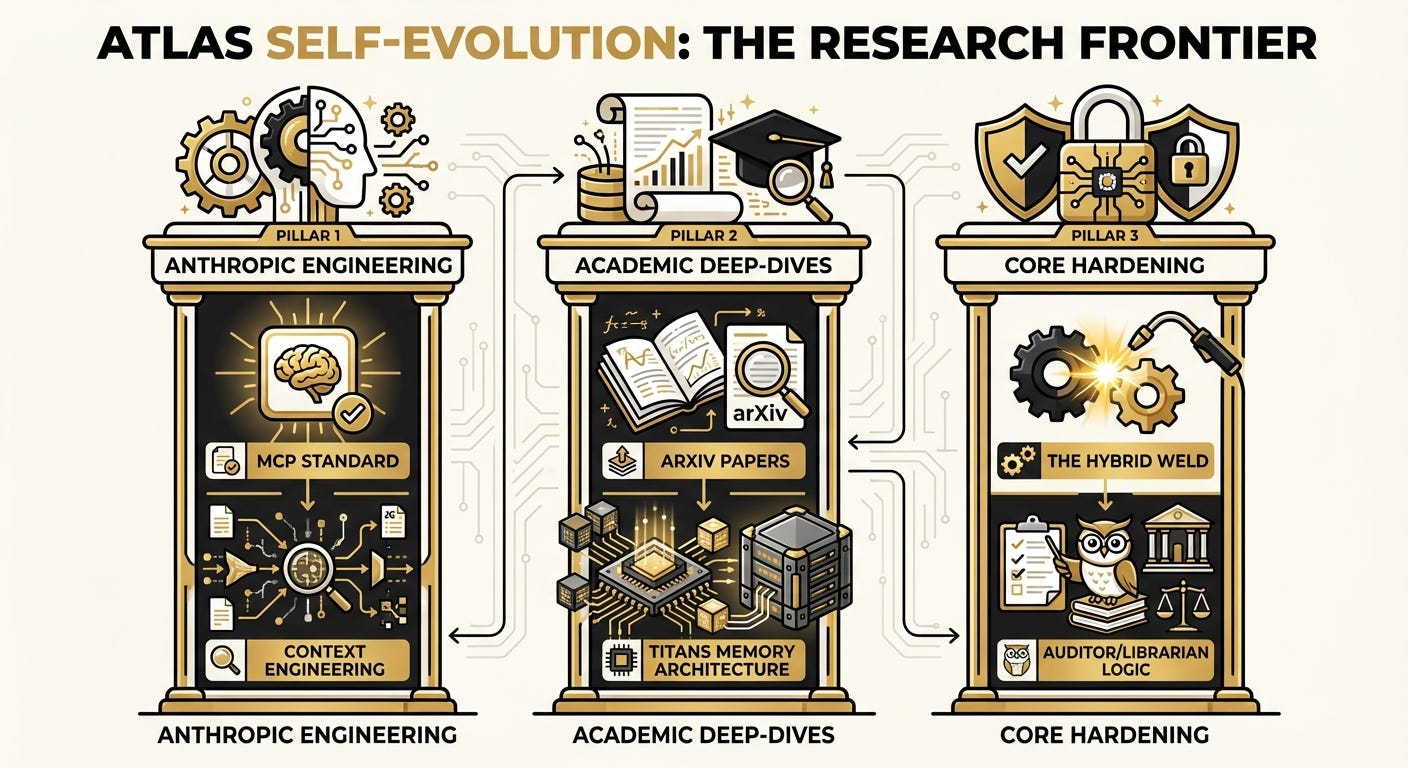
This image shows the three “pillars” Atlas uses for self-improvement: Anthropic engineering best practices (like MCP standards and context engineering), academic deep-dives (arXiv papers, new research like Titans memory architecture), and what it calls “core hardening” (reliability patterns, auditor logic, hybrid approaches to reduce hallucination).
Why This Matters for Operations Professionals
Atlas is a side project, not production infrastructure. It’s an experiment so I can understand first-hand where AI agents are headed and what’s possible today.
But the lessons transfer directly to the work I do every day:
Memory architecture matters. The same “memory drift” problem I hit with Atlas exists in any AI workflow that accumulates context over time. If your prompts are getting longer and your outputs are getting worse, you probably have a memory problem.
Code beats AI for retrieval. Using deterministic logic to fetch context rather than asking an LLM to figure out what’s relevant produces more reliable results. This applies to RAG systems, account research tools, and any workflow where precision matters.
Autonomy requires structure. Letting an AI “roam” (this is what Atlas calls the work it does during its Ticks) only works if you’ve built clear guardrails, audit functions, and state management. The same is true for any scaled AI workflow.
Looking Ahead
The agent landscape is moving fast. Google’s Agent Development Kit, Anthropic’s MCP protocol, and academic research like Titans (a new memory architecture paper) are all pushing toward AI that maintains state over time.
I don’t know exactly what this means for Marketing Operations or enterprises yet. But I think the skills that will matter in 2026 are the ones I’ve been developing this year: the ability to strategize, architect, and build systems, not just oversee their execution.
The ops professionals who learn to think in systems, who can design how data flows, how memory persists, how components connect, will have an enormous advantage. The tools are getting more powerful, but someone still needs to build the infrastructure that makes them useful.
That’s why I think 2026 will be the year we move from operators to architects.
I’ll be documenting my progress on Atlas and other projects as they develop, so stay tuned! If you’re building agents or experimenting with AI, I’d love to hear what you’re learning.