
Your Moat Isn't the Model
Anyone can build an impressive AI output in an hour. Your edge is what only you know.

I rebuilt one of my account intelligence reports, part of an account dossier suite I’ve built and written about before, as a live, interactive web page today.
It includes a company overview, financials, leadership, recent news, strategic priorities, an engagement history you can filter and sort, and outreach recommendations by persona. You can open it on your computer or phone (https://lilyl11-hub.github.io/account-intel-demo/). It took about an hour, start to finish.
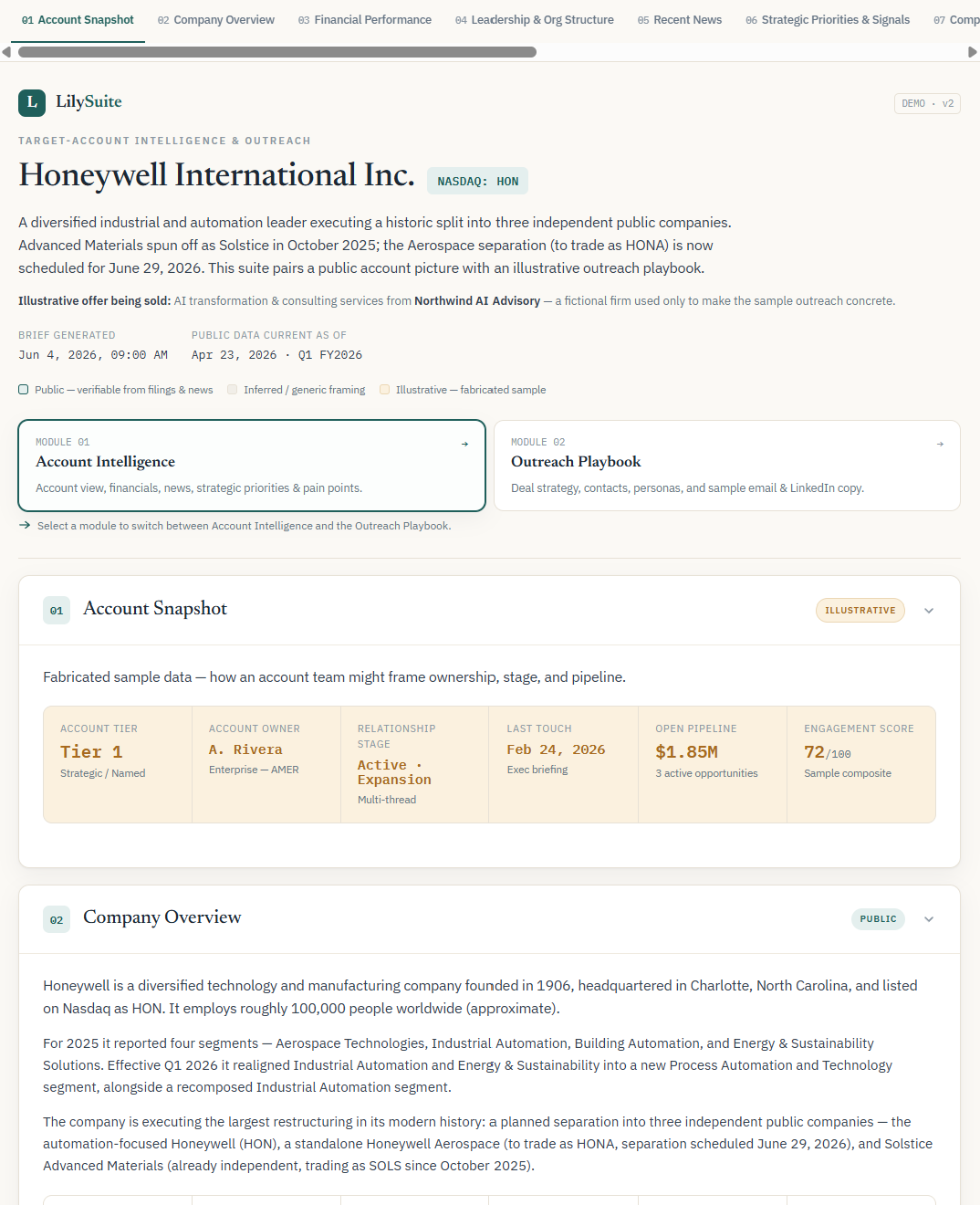
I’d like to tell you that’s the impressive part. But it isn’t. Anyone can build something similar in an hour or two, with the same tools I used, which means the output itself stops being the advantage.
It’s something I’ve been thinking a lot about recently. If we all have the same models, the same Copilot, the same Claude and Gemini, what is actually unique and substantive?
The answer isn't the model, and it isn't a new concept. Anyone who's spent time with these tools knows the output is only as good as what you ground it in — things like your audience, your voice, what you’ve learned, and your judgment. The model is mostly interchangeable. The grounding is the moat.
What I've been experimenting with connects this concept, taking something most people treat as a prompting habit and building it into a competitive advantage that scales past one person.
From static documents to dynamic artifacts
For a long time our deliverables have been static documents. PowerPoints, PDFs, the report files the tools I’ve built generate, email out, and save to SharePoint. You share one by sending the file or a link to it, and it’s frozen the moment it’s made.
What’s changing is the format and container. Outputs are becoming dynamic artifacts you can open, filter, and update without regenerating the whole thing, and that you can share like any web page instead of leaving them stuck in your own instance. In the brief I built, you can sort the engagement history by deal size and the news section shows how current it is, none of which is available in a PDF.
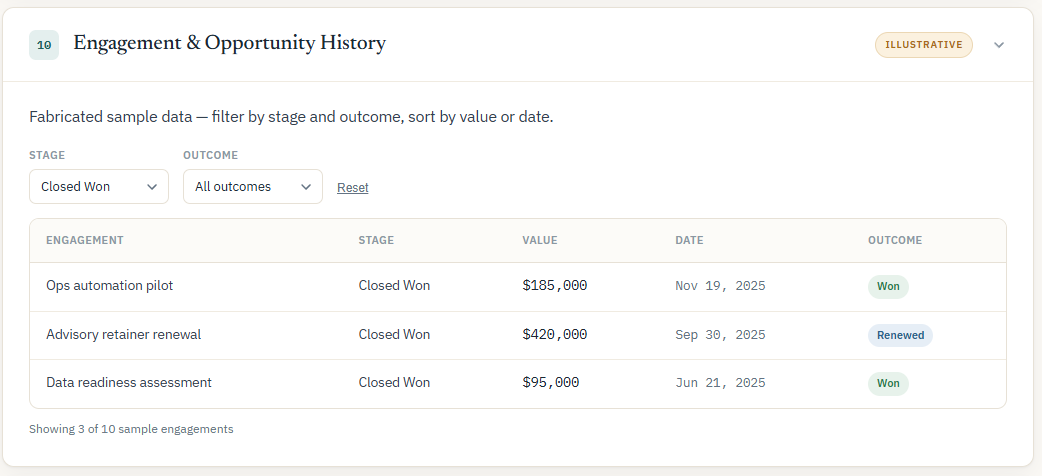
OpenAI is also building hosted, shareable artifacts into its product (Codex Sites), so this is where the major tools are heading. But it’s still a capability that everyone gets.
As for how I built the dashboard, I prototyped in the Claude web interface, the UI that I use to write and think through ideas, then moved it to Claude Code to productionize it and push it live. (Normally I’d do the whole project in Claude Code, but a lot of people use the web version, so I wanted to show that path works too.)
I also don’t just use one model for everything. I match each use case to the model that handles it best (and most of the time, for the least cost):
Gemini for fast, cheap web research and consistent extraction. I pair this with a verification step, like a Python check against the SEC API to confirm a company’s ticker symbol.
DeepSeek for cheap data analysis or coding work. Vigil, my operational agent, works really well on DeepSeek, at a low cost.
Haiku for fast, deterministic work. Ledger, my financial analysis agent, runs on Haiku because analyzing my finances needs determinism more than reasoning, at a fraction of the cost.
Opus, a slower, more expensive model for the steps that need more judgment and strategic thinking.
The fact that I swap models by task to save money tells you that the model isn’t the advantage. If it were, I wouldn’t trade it out for a cheaper one when I get the opportunity. And the AI landscape is also constantly changing. I cancelled my ChatGPT subscription, then resubscribed when useful new features were added, like goal setting, where the model works continuously toward an outcome you describe. OpenAI’s Codex created this feature, and Claude Code picked up.
Whatever’s best feature this month won’t be in 6 months. So you can’t build a moat on something interchangeable that’s changing under you.
Where the edge actually is
The part a competitor can’t copy by buying a subscription is what you ground the output in.
The brief I built runs on a public company's filings and sample records. It’s fine, but it’s also generic. The outreach recommendations are what anyone could generate from public data: reference their stated cost priorities, note the recent leadership change, suggest a value prop. Reasonable, but likely forgettable.
Now picture the same brief grounded in what your company actually knows. The recommendation isn’t “mention their cost priorities.” It’s the specific angle your team has closed three deals with in this segment, in the language your buyers actually respond to, citing the proof point that lifted reply rates in your last campaign, routed to the persona your data says converts. Same format, completely different output. The entire difference is in the grounding.
This context is what I think of as the knowledge layer, the codified version of what your company knows and decides. In a marketing function it is things like:
ICP and segmentation logic, current and with the reasoning behind it
Buyer personas, with their pains, language, objections, and buying triggers
Positioning and messaging, by segment, persona, and buying stage
Competitive intelligence: where you win, where you lose, and what to say
Brand voice, with examples of approved messaging and banned generic phrasing
Customer proof: case studies, stats, ROI numbers, with approval status
Plays: codified versions of what your best operators actually do
Performance learnings: what worked, what didn’t, and why
Codifying the learnings is where the compounding happens. Once you learn how a particular play, or a specific way of handling an objection, moves a deal forward, every brief built afterward reflects it, instead of each rep rediscovering it from scratch.
And the brief building effort isn’t really the moat either. The demo site took an hour, and an actual production version takes weeks of unglamorous plumbing, which I’ve written about before: wiring the inputs, ensuring accurate sources, QAing the outputs, making it hold up across hundreds or thousands of runs. But your competitor can build that same plumbing. What they can’t build is your version of the list above.
And most teams start with a misplaced first step. They start by connecting their data or choosing tools, which is important, but takes longer to set up and show results. The decisions worth redesigning usually aren’t blocked by missing data. They’re blocked by reasoning that lives in a few people’s heads and was never written down: the strategist who knows what good positioning looks like, the ops lead who knows which accounts actually close. Until that’s captured somewhere structured and current, the AI has nothing of yours to work from, and you get generic output no matter how good the model is.
What this unlocks
The brief I built is static, its data baked into the page. A production version of this pulls live account data on demand through the apps you connect and an automation layer like Zapier, and refreshes when you want it to. But most people can build that part. What they can’t copy is the brief that’s grounded in your knowledge layer, the codified version of how you target and position. The live data is the capability, but the grounding is the moat.
Take targeting, something every marketing team does. Today that’s a yearly or quarterly ICP exercise that produces an account list. The ABM, demand, and sales teams build against that list, and by the time campaigns are in market, the strategy is already old. New accounts are showing intent, priorities have moved, the messaging has evolved. Everyone is executing against last quarter’s picture.
Now picture it grounded and live. Account scoring runs continuously against your codified logic, refreshed against current signals and the latest company strategies. A seller opens the brief before a call and doesn’t get generic, public-data talking points. They get which accounts are rising and why, the angle that’s been closing deals in this segment this quarter, in your brand voice, routed to the persona your own data says converts. When leadership pivots, the briefs reflect it that week, not in 3 months.
At that point you’re not generating a report. You’ve taken the judgment your best strategist and ops lead carry around in their heads, written it down, and put it in front of your whole team, scaling your competitive advantage.
So if you want a head start on the part that’s unique, start by writing down what your best people know: how you position, why you win and lose, what your last campaign taught you. That list is the moat. The artifacts are just how you put it to work.
The format was always the easy part. What’s underneath is the differentiator, and it’s what I’ll be experimenting with next.