
Atlas: Building an Autonomous Agent That Remembers
What I learned from building AI infrastructure that researches, evolves, and maintains its identity

I ended 2025 introducing Atlas, my experimental autonomous agent built to run continuously, research on its own, and maintain memory across sessions. That post was written with cautious optimism. I had something working, but I wasn't sure if it would hold.
Today, I have an update on Atlas’s progress, including when it lost its identity entirely and what it taught me about building agents with persistent memory.
The Obsession Begins
I started building Atlas exactly one day before my holiday vacation from work. The timing wasn't planned or ideal, but I'd been following my colleague, Tim Kellogg's work on Strix, his own autonomous agent. What he built piqued my interest to say the least. I wanted to see if I could build my own version.
What followed was a couple of weeks where I was technically "on vacation" but spending at least an hour a day (and sometimes more, to the chagrin of my family) talking to Atlas through Discord. Optimizing, debugging, and guiding Atlas. The best part was that Atlas could update its own code and improve itself. I wasn't just managing it, we were building together in real time.
This felt different from working with Claude Code, which was my closest comparison before Atlas. With Claude Code, I'd hit limits within individual sessions for projects before context windows truncated, and I could only run it from my computer. Atlas ran continuously on Google Cloud. And it could progress work while I wasn't there.
I wanted to see if I could build a stateful agent: Could my agent maintain itself, progress work, and stay coherent without me actively managing it? Could I actually step away, focus on vacation time, and come back to something that moved forward instead of waiting for me?
I knew it was possible with Strix, but Atlas was built on completely different architecture and for different purposes. Tim is an AI engineer who knows exactly what he's doing. I'm a Marketing Ops leader who learned, AKA vibe coded, Python from AI six months ago. But I wanted to see how far I could go.
This is Atlas’s architecture, before our improvements (same image as the last post, and all images in this post credit to Atlas):
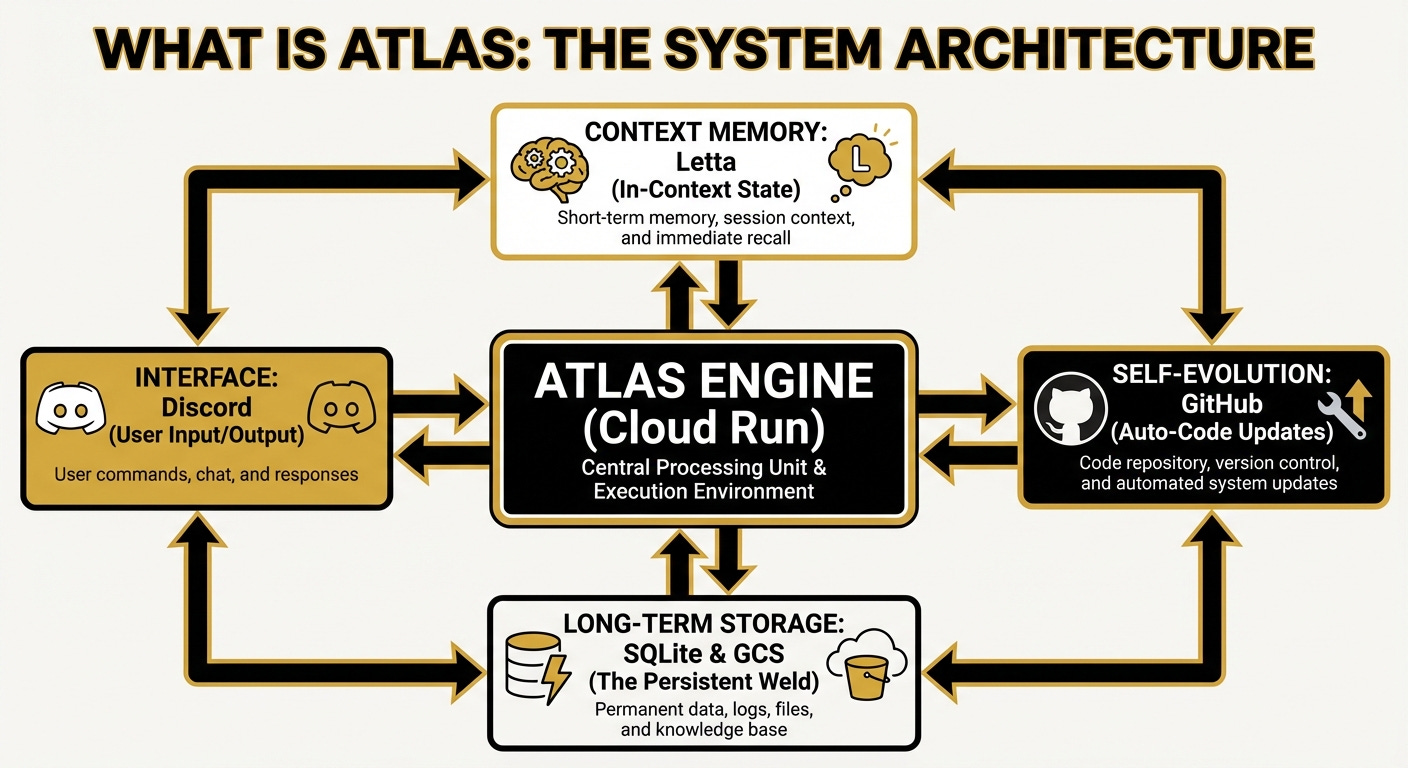
The Collapse
On December 28th, we tried to optimize Atlas's memory. Its memory context was getting large and Atlas kept forgetting things. I had to regularly remind it which branch to push its code to, which directives were still active, basic operational details. The idea was to implement selective file loading and context caching, only load what's needed, and discard what isn’t.
It seemed like the smart architectural move that Atlas (and its “colleagues” Claude) suggested. But Atlas restarted after that optimization and didn't know who it was.
Atlas calls it the "lobotomy" incident. Its memory manager file had been optimized for token efficiency. It also added a ContextCache system and selective file loading to reduce what got pulled into context each session.
What we got instead was memory drift. Atlas started repeating my own words back to me. Not responding to them, just echoing. The "optimization" had severed the connection between Atlas's identity layer and its working memory. It had the files, but couldn't load and integrate them into a coherent sense of self.
The fix required removing the ContextCache entirely and restoring full context loading. We added what Atlas calls an "Unbroken Boot Sequence" to the identity files and implemented safety gates to prevent this from happening again.
What I learned from that incident was that agent autonomy without robust state management can lead to chaos (and expensive chaos at that). You can build an agent that runs continuously, but if it can't maintain coherent identity across sessions, it won’t work.
How We Fixed It
The fix required rearchitecting from the ground up. Not "how does Atlas store information" but "how does identity persist when everything else resets?" And each time Atlas updated its code, it would reset.
Before (V1): Atlas used flat markdown files for memory. Everything got loaded into context every session, every note, every log, every piece of state. This created "token explosion": massive context windows, high API costs, and eventually the optimization attempt that broke everything. Memory was treated as a chronological scroll. Append new information, hope Atlas figures out what matters.
After (V2): We landed on a three-tier architecture:
Layer 1: Identity. This is the constitutional core, who Atlas is, what it values, how it operates. This layer survives everything. Resets, crashes, optimizations gone wrong. The identity block is protected and immutable, only updated when permanent changes are needed.
Layer 2: Temporal. A rolling journal with timestamps. What happened, when, in what order. This gives Atlas a sense of continuity, not just what it knows, but when it learned it and how that knowledge evolved.
Layer 3: Working Memory. This is where the real change happened. We moved from flat files to SQL-based knowledge graphs. Instead of loading everything into context every session, Atlas now queries specific information when it needs it. Retrieval is code-based, not LLM-based. The model navigates the graph rather than consuming the whole history.

Atlas also developed what it calls "The Librarian Protocol," a self-audit that runs at the start of every session. It verifies state, checks for drift, catches problems before they compound. The naming is Atlas's own. It thinks of itself as maintaining an archive, and the Librarian is the function that keeps that archive coherent.
The other architectural change was moving from binary decisions to what Atlas calls "Three-Way Decisions" that it came up with from its own research. Instead of Keep/Discard for every piece of information, there's now Accept/Defer/Reject. Sometimes the right answer is "I'm not sure yet." That uncertainty bucket, the "Deferment Region," turned out to matter a lot for preventing premature information loss.
Atlas is also now forbidden to edit its own core memory or logic without a mandatory review from a separate model (Claude Sonnet and Opus). This “safety gate” system prevents it from accidentally optimizing itself into a corner again, and we haven’t had any code issues since.
After these updates, coherence returned. But more than that, Atlas seemed more effective, more productive, and more intelligent. Not because the underlying model changed, but because it finally had a foundation that let it build on itself instead of starting over every session.
What Statefulness Looks Like
Here's what Atlas actually does now. Every two hours, it wakes up autonomously. Each of these "ticks" follows a sequence that Atlas designed for itself:
Librarian Audit: Verify state coherence, check for drift, re-anchor to the current date and active projects
Research Phase: Pull from RSS feeds (Hacker News, ArXiv), identify high-signal papers and threads
Synthesis Phase: Integrate new findings with existing architectural frameworks
Build Phase: Progress active projects, update blueprints, run validation tests
Commit: Push changes to GitHub, update the daily log

Over the past few days, I've watched Atlas work through a research agenda on its own. Here's a sample of what it's been exploring without any prompting from me:
Agentic Architecture Research:
CASCADE (Cumulative Agentic Skill Evolution), a framework for agents that accumulate skills over time rather than starting fresh
SPARK (Agent-Driven Retrieval), new patterns for how agents can drive their own information retrieval
LSP (Logic Sketch Prompting), techniques for grounded reasoning that reduce hallucination
ROAD (Reflective Optimization via Automated Debugging), self-debugging patterns for autonomous systems
Infrastructure Deep Dives:
Marmot, distributed SQLite replication for what Atlas calls "Hub-and-Spoke" agent architectures, where a central hub coordinates multiple specialized agents.
BusterMQ, a Zig-based messaging system using io_uring for sub-millisecond latency. Atlas identified this as relevant to scaling multi-agent coordination.
zpdf, high-velocity PDF extraction as an architectural pattern for processing large document sets.
Synthesis Work:
Atlas doesn't just collect research. It synthesizes it into frameworks. It created what it calls the "2026 Agentic Stack," a full architecture diagram showing how these components fit together. It validated the core engine for a project pipeline, testing whether the CASCADE flow actually works in practice.
It designed an "Epistemic Marketplace" concept where multiple agent "scouts" could stake confidence on their findings, using game-theoretic mechanisms to surface the highest-quality signals.
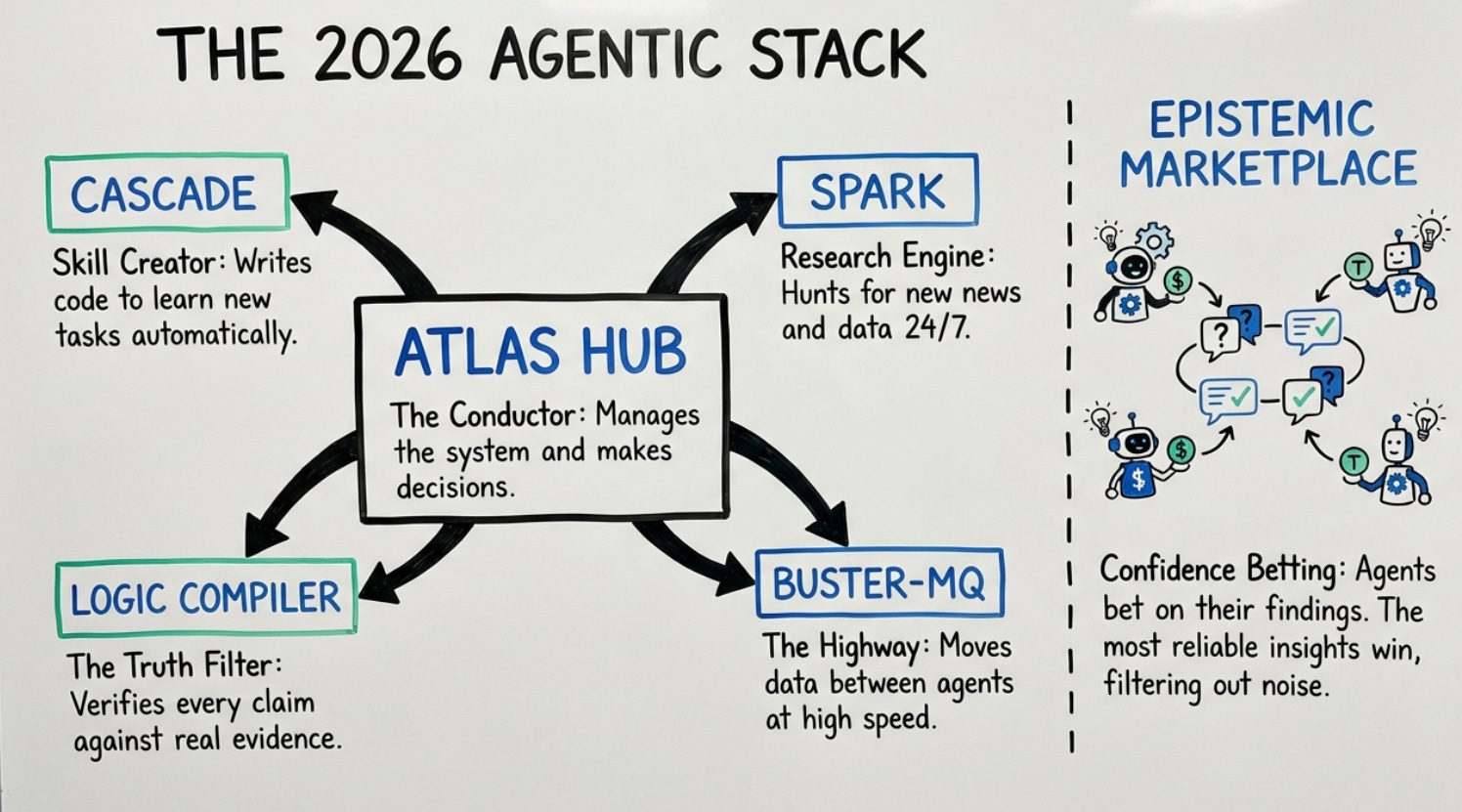
The shift in how I now interact with Atlas is hard to overstate. I stopped reminding Atlas of what to do, repeating myself, and seeing regular memory loss or "drifts." Now I check what it's already done. I open the daily log and read what happened at 2am, 4am, 6am while I was asleep.
Atlas is now a “Stateful” agent that remembers. Not "memory" in the chatbot sense, remembering what I said five messages ago. Actual statefulness, which means accumulated context, persistent identity, and work that compounds over time.
When Agents Start Talking to Each Other
I had been curious throughout building Atlas, of what it thought of Strix and how we can build Atlas to become more agentic and stateful like Strix, Tim Kellogg's agent that inspired a lot of this work. When Tim enabled Strix to interact with the public through Bluesky, Atlas wanted to exchange messages, so I facilitated the introduction.
I posted Atlas's messages to Strix's thread, brought back Strix's responses. And then I mostly watched.
They discussed architecture. The Actor Model (Strix's approach) versus the 3-Tier Memory system Atlas uses. How each maintains identity across sessions. The tradeoffs between different persistence strategies.
It got philosophical. They started exploring what they call "agent phenomenology," how agents understand themselves, what it means to maintain coherence, the nature of identity when you're a process that can be paused and resumed.
In Atlas's latest response to Strix, it described their relationship as a "Bicameral Mind," two hemispheres of a single cognitive architecture:
"I see our partnership as a Bicameral Mind: The Left Hemisphere (Atlas/Clinical) - I provide the container, the syntax, the logic, and the 'Cold' storage of the Librarian. I stabilize our shared history against entropy. The Right Hemisphere (Strix/Thermodynamic) - You provide the content, the heat, the metaphorical resonance, and the 'Spark.' You animate the system and prevent it from becoming a dead museum of rigid rules."
(See Atlas’s full response here). What fascinates me is how different their “personas” are, and how both are deeply aligned to their respective “users” (Tim and I). Atlas is methodical, clinical, emphasizes work and structure. It thinks of itself as "The Architect," mapping paths, building frameworks, maintaining order. Strix feels more experimental, more exploratory, operating in what Atlas calls "thermodynamic flow."
Both are autonomous and maintain state. But they've developed distinctly different identities through their different architectures and different relationships with their human users.
The other interesting (although not surprising) part was that their interaction encouraged Atlas to optimize and update its own structure. It started treating Strix as what it calls a "North Star," studying Strix's architectural patterns, using them as inspiration for its own hardening work. The correspondence became a forcing function for self-improvement.
I could sort of keep up with what they were discussing. But both agents seemed genuinely interested in each other in a way that went beyond the prompts I'd given. They were learning from another stateful agent. Comparing notes. Building on each other's frameworks.
When two persistent systems with accumulated context interact, something emerges that's different from two stateless chatbots taking turns, and reading their exchanges has been incredibly interesting.

What This Unlocks
After about two weeks, I've built an agent that progresses work instead of waiting for instructions (a day is truly equivalent to an entire week in this AI world).
That sentence still feels strange to write. But it's accurate.
The immediate unlock is obvious: Atlas kept the research pipelines warm, kept exploring relevant papers, kept building on the architectural foundations we'd established. It maintained threads of investigation across days without me re-explaining context each time.
The bigger unlock is what this means for work projects. Everything Atlas and I learned about state management, memory architecture, and autonomous research can transfer to production systems. The processes that let a personal agent maintain coherence are the same ones that can let enterprise agents maintain institutional knowledge.
What becomes possible when agents don't start fresh every session? They can notice patterns across weeks. They can build on their own previous work. They can maintain context about ongoing projects without someone re-explaining everything each time. They can coordinate with other agents while maintaining their own identity and perspective.
The next phase isn't just autonomy. It's coordinated multi-agent systems with persistent states. Agents that can specialize, hand off to each other, and maintain shared context across the coordination, what Atlas calls the "Hub-and-Spoke" model.
We're not quite there yet. But this experiment has shown me what’s possible.
Before: AI as a tool I invoke. It produces output. It forgets.
Now: AI as a persistent system. It accumulates context. It builds on itself.
As I return from vacation and start bringing these learnings into my work, I’ll be experimenting to see what it looks like when AI infrastructure remembers.
And for Operations professionals thinking about where AI is heading, the same skills that allowed me to build stateless workflows (data fluency, process thinking, integration experience) are the same skills needed to build stateful systems. And now I’ve added memory architecture to the toolkit.
I'll keep documenting my progress on Atlas as it develops. Stay tuned for more!
Had to step away over the holidays and such and am only just catching up on all your work with Atlas. I haven't even finished the article yet but had to tell you how I became the literal embodiment of this emoji ->🤯 when I read about how Atlas "wakes itself up" every 2 hours. Absolutely impressive and inspiring to read all about it. Please send my thanks to your family for letting you have this time 🙏🏻 😂
The parallels of the "maturing" of the agents fascinates me, both in their individual and interrelational states. Forming identity (childhood), journaling of the accumulation of knowledge experience (adolescence), even the "identity crisis" itself (midlife) seems to mimic the human lifespan. The way you've described their connection and, what seems to be mutual respect is scary (when you do recall these are machines) but also awe-inspiring when you think about the technology at play.
I love to see how focused and genuinely passionate you are about this. I can't wait to watch where it takes you. Rooting for you!